
Kuromoji is an open source Japanese morphological analyzer written in Java.
Kuromoji has been donated to the Apache Software Foundation and provides the Japanese language support in Apache Lucene and Apache Solr 3.6 and 4.0 releases, but it can also be used separately.
We are a small R&D and consulting company based in Tokyo.
We are proficient in the fields of search, natural language processing, big data and more. Please see our homepage for more info.
Please feel free to contact us on kuromoji at atilika dot com if you have questions or feature requests. 日本語でも大丈夫です。
Kuromoji supports standard morphological analysis features such as
Enter Japanese text below in UTF-8 and click Tokenize.
Tip This demo is also available separately on http://atilika.org/kuromoji
Try Kuromoji from the command line using the below commands, and then write some text followed by RET.
% java -cp kuromoji-0.7.7.jar org.atilika.kuromoji.TokenizerRunner Tokenizer ready. すもももももももものうち すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ も 助詞,係助詞,*,*,*,*,も,モ,モ もも 名詞,一般,*,*,*,*,もも,モモ,モモ も 助詞,係助詞,*,*,*,*,も,モ,モ もも 名詞,一般,*,*,*,*,もも,モモ,モモ の 助詞,連体化,*,*,*,*,の,ノ,ノ うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
Info You may need to add option -Dfile.encoding=UTF-8 to get a suitable output in your terminal, depending on your system.
For search applications, it's often useful to do additional splitting of words to make sure you get hits when searching compounds nouns.
For example, we want a search for 空港 (airport) to match 関西国際空港 (Kansai International Airport), but most analyzers don't allow this since 関西国際空港 tend to become one token. This problems is also applicable to a katakana compounds such as シニアソフトウェアエンジニア.
Kuruomoji supports segmentation modes that gives different segmentations based on the application in mind:
The below table gives some examples of these modes.
| Untokenized | Normal mode | Search mode | Extended mode |
|---|---|---|---|
| 関西国際空港 | 関西国際空港 | 関西 国際 空港 | 関西 国際 空港 |
| 日本経済新聞 | 日本経済新聞 | 日本 経済 新聞 | 日本 経済 新聞 |
| シニアソフトウェアエンジニア | シニアソフトウェアエンジニア | シニア ソフトウェア エンジニア | シニア ソフトウェア エンジニア |
| ディジカメを買った | ディジカメ を 買っ た | ディジカメ を 買っ た | デ ィ ジ カ メ を 買っ た |
Kuromoji provides the Japanese language support in the upcoming Apache Lucene and Apache Solr search products (3.6 and 4.0).
The Kuromoji integration in Lucene/Solr ships with a ready-to-use default configuration that does:
Additional to the above, there are lots of useful token attributes with readings, romanized readings, part-of-speech, etc. The above is available in Lucene as JapaneseAnalyzer and a default field "text_ja" in Solr's example schema.xml. Configuration options are of course also available.
Tip To search Japanese using Solr, simply use field type "text_ja".
Tip To search Japanese using Lucene, all the above is available using JapaneseAnalyzer.
In search mode, we want to split compounds in order to make their parts searchable, which is good for recall.
In order to make sure we maintain precision for an exact term match, we also keep the compound in our index as a synonym to get a rank boost (typically from IDF).
Kuromoji makes recall and precision considerations for overall good ranking.
| Position 1 | Position 2 | Position 3 |
|---|---|---|
| 関西 | 国際 | 空港 |
| 関西国際空港 | ||
Below is an analysis screenshot of Solr 4.0 for the text 関西国際空港から出発した (I departed from Kansai International Airport).
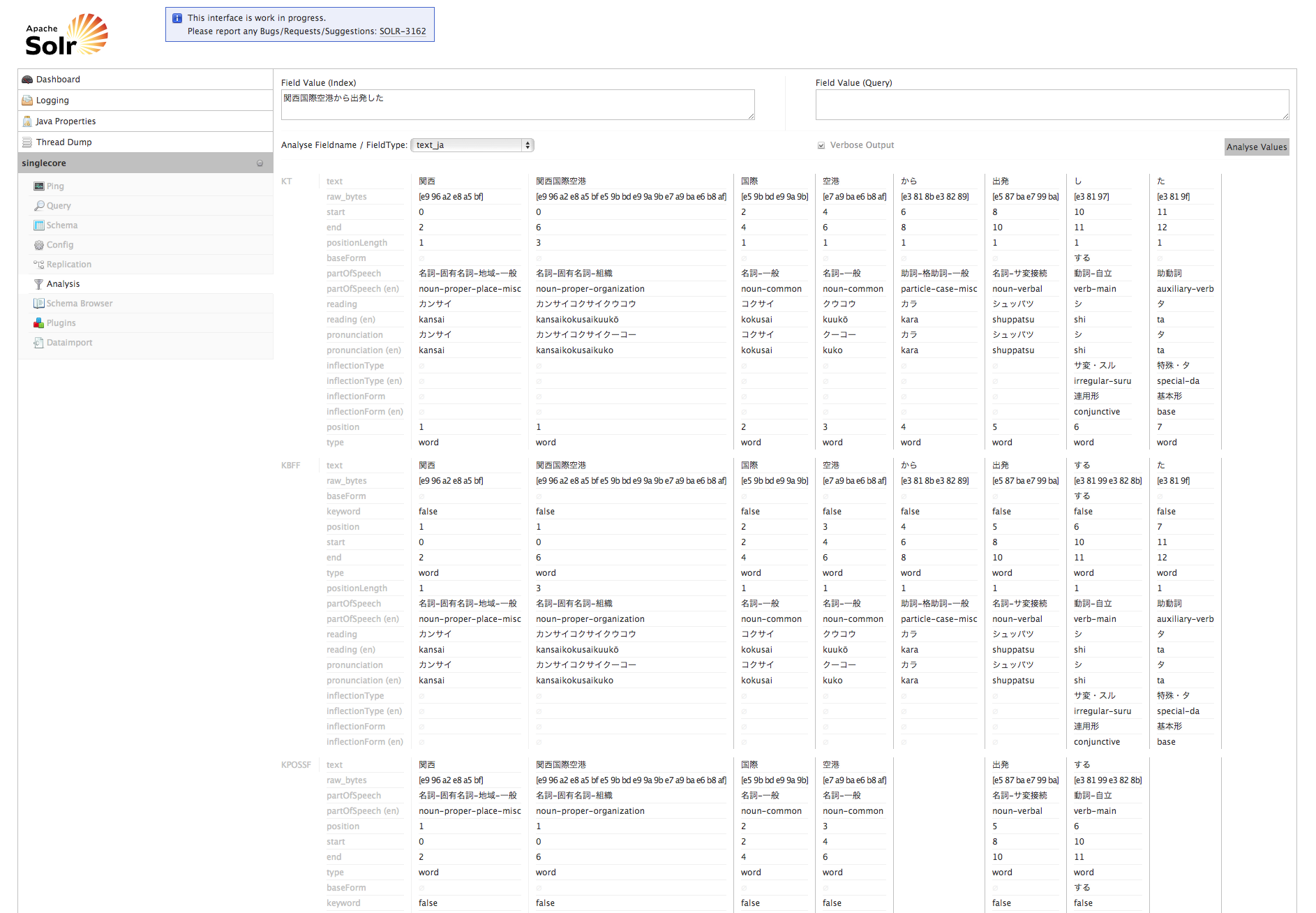
Info Several token attributes available, including part-of-speech tags, readings, romanized readings, etc.
Kuromoji is packaged as a single jar file, is Mavenized (see below), and doesn't have 3rd party dependencies to make it easy to work with.
Below is a simple Java example that demonstrates how a simple text can be segmented.
package org.atilika.kuromoji.example;
import org.atilika.kuromoji.Token;
import org.atilika.kuromoji.Tokenizer;
public class TokenizerExample {
public static void main(String[] args) {
Tokenizer tokenizer = Tokenizer.builder().build();
for (Token token : tokenizer.tokenize("寿司が食べたい。")) {
System.out.println(token.getSurfaceForm() + "\t" + token.getAllFeatures());
}
}
}
Compile the example program using
% javac -encoding UTF-8 -cp lib/kuromoji-0.7.7.jar src/main/java/org/atilika/kuromoji/example/KuromojiExample.java
and then run it using
% java -Dfile.encoding=UTF-8 -cp lib/kuromoji-0.7.7.jar:src/main/java org.atilika.kuromoji.example.KuromojiExample 寿司 名詞,一般,*,*,*,*,寿司,スシ,スシ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ 。 記号,句点,*,*,*,*,。,。,。
Tip Kuromoji is thread-safe so you can tokenize text from multiple threads.
To use Kuromoji with Maven, first add the repository to the <repositories> section of your pom.xml as indicated below.
<repository>
<id>Atilika Open Source repository</id>
<url>http://www.atilika.org/nexus/content/repositories/atilika</url>
</repository>
Then add the Kuromoji coordinates to the <dependencies> section as follows:
<dependency>
<groupId>org.atilika.kuromoji</groupId>
<artifactId>kuromoji</artifactId>
<version>0.7.7</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
You should now be able to use Kuromoji in your project.
Various additional information about Kuromoji is provided below.
Kuromoji is licensed under the Apache License v2.0 and uses the MeCab-IPADIC dictionary/statistical model. See NOTICE.txt for license details.
Kuromoji supports the MeCab-IPADIC dictionary and has experimental support for UniDic. Contact us if you need additional dictionary support.
Kuromoji is thread-safe.